




One of my favorite new tools is Mage AI, an “open-source data pipeline tool for transforming and integrating data.” What I appreciate the most is their first-class documentation. They make it easy to get up and running in no time with extensive help and support for multiple platforms and providers. However, the reason I’m sharing this write-up is that the current version of the Mage docs does not cover key aspects of what it took to implement my scenario.
For my use case, we are running on GCP using their GKE implementation of Kubernetes. My goal was to provide a small, reasonably priced cluster for persistent resources such as the Mage web server and scheduler, while also offering the ability to dynamically scale pipeline workloads on high-memory nodes that only spin up during the lifespan of the pipeline.
To accomplish this I have set up two separate node pools (naming things was never my strong suite):
pool-1 Comprising small, horizontally scalable nodes with enough CPU/Memory to handle the main Kubernetes overhead and the main Mage web and scheduler services.
pool-2 Comprising large high-memory nodes to satisfy the hungriest of our data prep workloads. This pool is configured to auto-scale to 0 nodes.
Unfortunately, even with the auto-scale on pool-2 set to 0 and the GKE Autoscaling Profile set to “Optimize utilization”, pods might still be assigned to pool-2 even if they don’t need to be. That is where taints, tolerations, and affinity come in.
Taints & Tolerations
In Kubernetes, taints and tolerations work together to control pod placement on nodes. Taints are applied to nodes to repel certain pods, while tolerations are applied to pods to allow them to be scheduled on nodes with matching taints. This mechanism ensures that pods are only scheduled on appropriate nodes, improving resource management and workload isolation.
So for pool-2, we add a taint (which is a key=value pair) of “high-memory=true”. That means that any pod that wants to schedule on a pool-2 node needs to have a corresponding toleration of the same key=value pair.
In the GCP console, node taints are added by editing the node pool and scrolling down to the “Node taints” section as shown below:
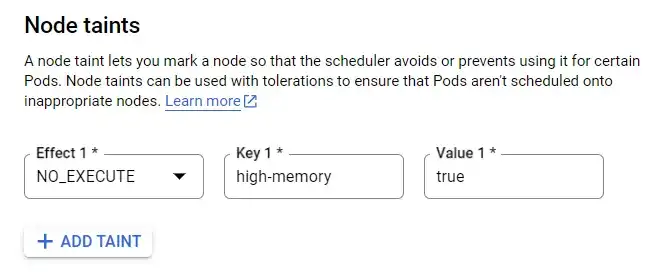
If we just leave it like that, then nothing will ever get scheduled on pool-2 and the node count will remain at 0. Unless we attempt to schedule pods with a corresponding toleration, the node pool will remain empty.
Mage AI allows to you specify Kubernetes executor configs in your metadata.yaml files. This is where we apply the tolerations to ensure that the appropriate pods can be scheduled on pool-2 nodes.
k8s_executor_config:
job_name_prefix: data-prep
namespace: default
resource_limits:
cpu: 4000m
memory: 8192Mi
resource_requests:
cpu: 250m
memory: 128Mi
service_account_name: default
pod:
tolerations:
- key: "high-memory"
operator: "Equal"
value: "true"
effect: "NoExecute"So, now the data prep pods will be scheduled with tolerations that match the taints of our high memory nodes. However, that is still not enough to guarantee that they will be placed on pool-2. There might be enough capacity in pool-1 to handle the initial resource_requests however it might not handle the eventual demands if it is a heavy pod. The workload will still get assigned to pool-1 because our pool-2 is still scaled down to 0 and the scheduler will prefer a running node.
Affinity
This is where affinity comes in. Node affinity allows you to constrain which nodes your pods are scheduled on, based on node labels. We define those labels in almost the same way as the taints from earlier, using the Edit Node Pool in the GCP console:
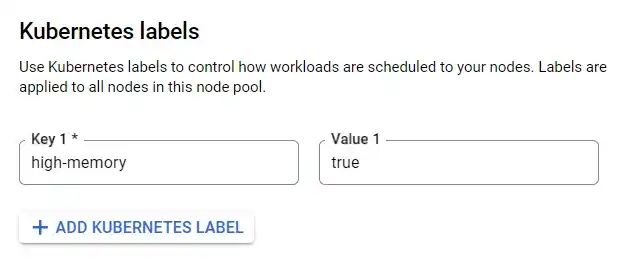
So just like taints, labels are key=value pairs. And again, since I’m not very good at naming things, we’ll stick with “high-memory” for our label as well.
We now need to place the corresponding affinity setting in our k8s_executor_config. We will append another section to the pod settings as shown below:
k8s_executor_config:
job_name_prefix: data-prep
namespace: default
resource_limits:
cpu: 4000m
memory: 8192Mi
resource_requests:
cpu: 250m
memory: 128Mi
service_account_name: default
pod:
tolerations:
- key: "high-memory"
operator: "Equal"
value: "true"
effect: "NoExecute"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "high-memory"
operator: "In"
values:
- "true"Lastly, just to be clear, you need to make sure you have selected “k8s” as your Mage AI executor type:
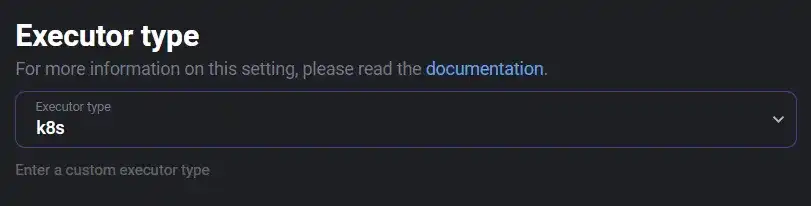
That can be at either the block or the pipeline context.
Summary
So to wrap up, we have the following:
- Two node pools: One with small, inexpensive nodes and another with large, expensive nodes.
- Taints on the expensive nodes: To “repel” workloads that don’t “tolerate” them.
- Matching tolerations: On the specific workloads that need the heavy nodes.
- Affinity labels: So our heavy workloads will prefer the heavy nodes.
- Auto-scale to 0: On the large, expensive node pool so it stays dormant while no pipelines are running.